
🌻 E40 - Is ChatGPT Changing the Way We Speak?
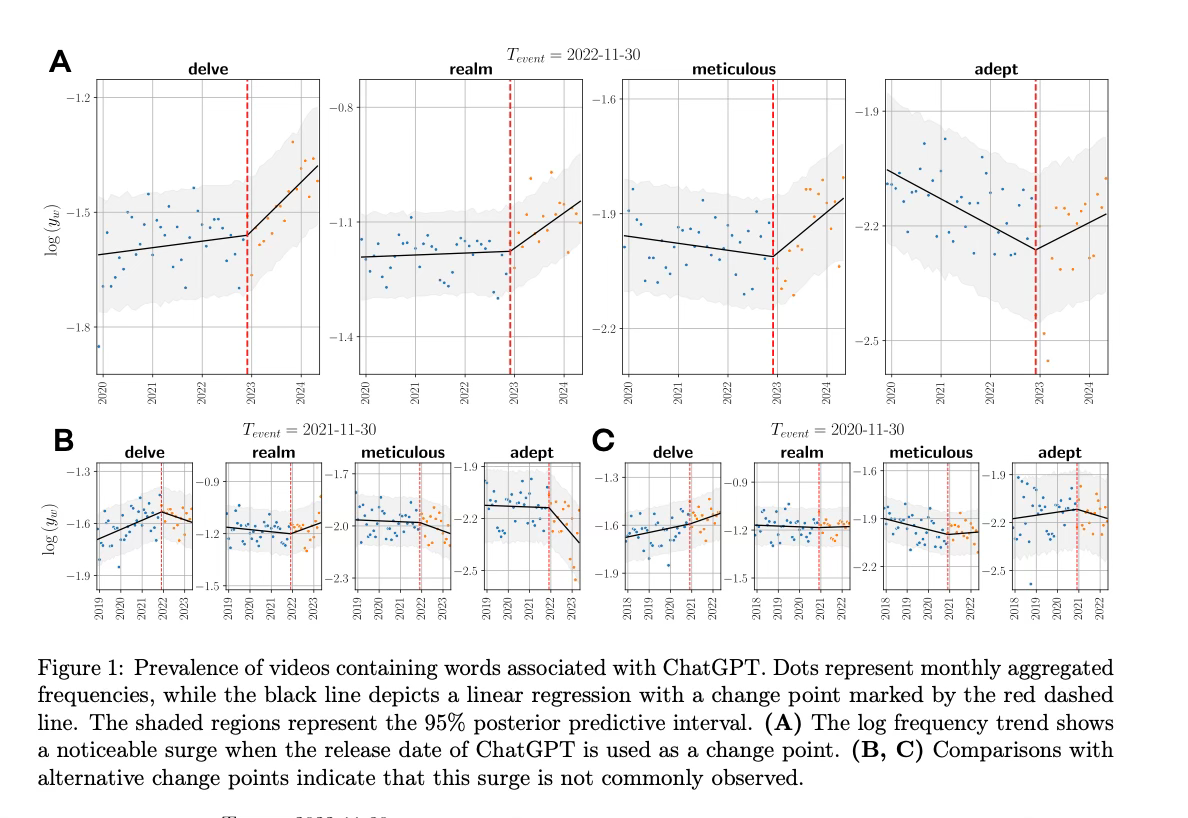
Have you noticed how often words like ‘delve’ and ‘realm’ are being used lately?

Every day, ChatGPT handles more than 1.5 million requests. Think about that for a second.
Just this morning, I used a tool called Cursor seven times in the span of two hours while building an application. You’re likely using AI tools too—maybe even without realizing it. Whether we’re typing out prompts or letting these AI systems assist us, one thing is clear: they’re deeply integrated into our lives. And now, it’s starting to show in an unexpected way—our language.
That raises a fascinating question: Could ChatGPT actually be changing the way we speak?
To answer this, researchers from the Center for Humans and Machines and the Center for Adaptive Rationality at the Max-Planck Institute for Human Development in Germany dove into the data. They analyzed a massive set of 280,000 English-language videos—presentations, talks, and speeches—coming from over 20,000 YouTube channels, all tied to academic institutions.
What they found was significant. Certain words, patterns, and styles of communication unique to AI, especially ChatGPT, are starting to seep into how we speak. It’s subtle, but it’s there. And it may just be the beginning of a much larger shift in human culture.

🌸Choice Cuts
🌼 Bigger Isn’t Always Better: Rethinking Synthetic Data Generation
I’ve always had this intuition: a bigger model can generate better synthetic data.
It makes sense, right? When we’re training a smaller, task-specific model—especially for something like math or programming—we rely heavily on synthetic data. This data helps cover all the permutations and combinations of real-world scenarios.
We even apply different strategies like Chain of Thought (CoT) or ReACT as template to the synthetic datasets to optimize training. So naturally, I thought a larger model would be able to generate richer variations of data.
But I overlooked one critical issue: bigger models can also hallucinate more.
That’s where smaller models come into play. When fine-tuned for a specific task, they can actually generate more reliable synthetic data without the risk of hallucinations.
Google even experimented with this approach, and the results were eye-opening. Smaller, task-specific models can offer a more precise, cost-effective solution for synthetic data generation.
It’s a fascinating shift in thinking—bigger isn’t always better, especially when it comes to training models for specific tasks.
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling