
💨 The 6th Edition `RIP Pandas - Learn Polars` - Part 1
RIP Pandas as pd


I saw this post last year.

And then I began analysis on this topic - I found the goldmine - And discovered `Polars`. I have not been using Pandas for the last six months. Polars is my tool.

🚀 It’s Really Fast

🔸 Powerful data manipulation and analysis library.
🔸 Written in Rust (created by Ritchie Vink)
🔸 Uses Apache Arrow - native arrow2 Rust implementation.
🔸 Available with multiple languages: python, rust, and NodeJS.
🔸 Memory efficiency: Similar to Arrow, which reduces memory overhead and improves memory utilization.
🔸 Expressive API: Chains of expressions build an optimized query plan
🔸 Interoperability: Integrates seamlessly with other data processing frameworks, such as Apache Arrow, enabling efficient data interchange between different systems
🧄 Parallelization
We always aim for multithreaded code that runs into multiple cores - But in practical life, we don't get the best results with it perfect parallelization is a myth.
⭕ Without Parallelization

In pandas you can use the codes without parallelization - but the execution time will be higher and other cores will be unutilised.
😔 Multi-core Parallelization done wrong
Thats why we want to use parallel computing to allocate task on all the cores.
That is why we run code in a parallel way rightly is complex rather than That's why we want to use parallel computing to allocate tasks on all the cores. Some libraries like Dask and Modin can be used in a parallel way. but we need to ensure that we do parallelize our work in the right way so its not hiding the drawbacks and putting the sugar on top of that to make it work to some extent.
Now let me tell some basics of parallelization theory in the data frame domain.
Scenario: We have data for column `x` and `y` and there are three keys `a`, `b` and `c` . We need to first goupby and then apply the `sum` process.
🚂 Basic Embarrassingly Parallel

We can use here basic map reduce technique - split the data and then we can complete the operation.
🔸 Aggregations across different columns.
🔸 Groupby operations can be parallelized.
🔸 This is the ideal scenario - because all the data is in the stored order so splitting the data with the keys relay easier. Let's look at some real word situations where the data is mixed.
👉 Parallel Hashing
Hashing is the core of many operations in a DataFrame library, a groupby-operation creates a hash table with the group index pointers, and a join operation needs a hash table to find the tuples mapping the rows of the left to the right DataFrame.
🛸 Expensive Synchronization
In both operations, we cannot simply split the data among the threads. There is no guarantee that all the same keys would end up in the same hash table on the same thread. Therefore we would need an extra synchronization-phase where we build a new hashtable. This principle is shown in the figure below for 2 threads.

🔸 In real world the data would be mixed.
🔸 Data split into thread(CPU core) s.
🔸 Each thread applies operations independently.
🔸 There is no guarantee, that a key doesn’t fall into multiple threads.
🔸 Extra synchronization step necessary and complicated to build.
🎇 Expensive Locking
Another option that is found too expensive is hashing the data on separate threads and have a single hash table in a
mutex. As you can imagine, thread contention is very high in this algorithm and the parallelism doesn’t really pay of.

🔸 To provide the solution of the expensive synchronization the Expensive locking mechanism was built.
🔸 Data is split into threads.
🔸 Threads have shared storage (mutex) to prevent duplicates.
🔸 But different threads block each other.
🔸 It will be fine when you have 2-4 cores - but if you have to execute on 24-32 cores, there will be complications due to large inter-thread communication messages.
🌠 Lock-free hashing
Instead of the before mentioned approaches, Polars uses a lock-free hashing algorithm. This approach does do more work than the previous Expensive locking approach, but this work is done in parallel and all threads are guaranteed to not have to wait on any other thread. Every thread computes the hashes of the keys, but depending on the outcome of the hash, it will determine if that key belongs to the hash table of that thread. This is simply determined by the
hash value % thread number. Due to this simple trick, we know that every threaded hash table has unique keys and we can simply combine the pointers of the hash tables on the main thread.
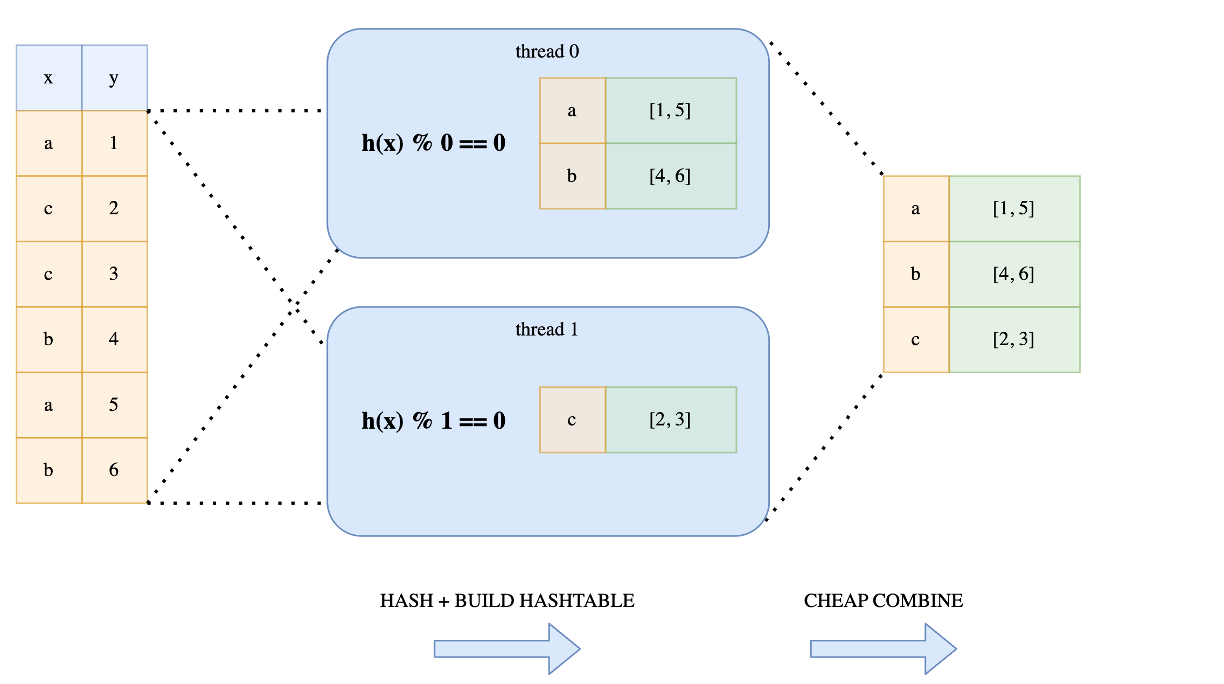
🔸 Thats why Ploars has developed this technique called Lock-free hashing.
🔸 All threads read the full data.
🔸 Threads independently decide which value to operate on by a modulo function.
🔸 Results can be cheaply combined by trivial concatenation.
That’s All I want!
🔸 select/slice columns: select
🔸 create/transform/assign columns: with_columns
🔸 filter/slice/query rows: filter
🔸 grouping data frame rows: groupby
🔸 aggregation: agg
🔸 sort the data frame: sort

Lets Install It
!echo "Creating virtual environment"
!python -m venv polars_env
!echo "Activate the virtual environment, upgrade pip and install the packages into the virtual environment"
!source polars_env/bin/activate && pip install --upgrade pip
!pip install polars connectorx xlsx2csv pyarrow ipython jupyterlab plotly pandas matplotlib seaborn xlsxwriter RISE
Restart the Karnel and The try to call
import polars as pl
import pandas as pd
import numpy as np
import plotly.express as px
Next Editions (Series of 4)
We will learn →
Second Edition
🔸 Lazy mode 1: Introducing lazy mode
🔸 Lazy mode 2: evaluating queries
🔸 Introduction to Data Types
🔸 SeriesandDataFrame🔸 Conversion to & from Pandas and Numpy
🔸 Filtering rows 1: Indexing with
[]🔸 Filtering rows 2: Using
filterand the Expression API🔸 Filtering rows 3: using
filterin lazy mode
Third Edition
🔸 Selecting columns 1: using
[]🔸 Selecting columns 2: using
selectand expressions🔸 Selecting columns 3: selecting multiple columns
🔸 Selecting columns 4: Transforming and adding a column
🔸 Selecting columns 5: Transforming and adding multiple columns
🔸 Selecting columns 6: Adding a new column based on a mapping or condition
🔸 Sorting
🔸 Missing values
🔸Replacing missing values
🔸 Replacing missing values with expressions
🔸 Transforming text data
🔸 Value counts
Forth Edition
🔸 Groupby 1: The
GroupByobject🔸 Groupby 2: Aggregation and expressions
🔸 Groupby 3: Multiple aggregations
🔸 Groupby 4: The
LazyGroupByobject🔸 Concatenation
🔸 Left, inner, outer, cross and fast-track joins
🔸 Join on string and categorical columns
🔸 Filtering one
DataFrameby anotherDataFrame🔸 Use an expression in another
DataFrame🔸 Extending, stacking and concatenating
**
I will publish the next Edition on Sunday.
This is the 6th Edition, If you have any feedback please don’t hesitate to share it with me, And if you love my work, do share it with your colleagues.
Cheers!!
Raahul
**