
🌻 Edition 26: LLMLingua - A Zip Technique for Prompt 🌟
A underrated beautiful framework for prompt Compression of last year

Oops, I've been playing hide and seek! 🙈 Big news is brewing! 🌪️ Aiming to be your regular dose of awesomeness this year. 🚀 Huge shoutout for your epic support – you rock! 🌟 Get ready, cool stuff is simmering in the draft pot – Coming soon! 🚗💨 Buckle up, it's gonna be a wild ride! 🎢
Yeah, you are thinking it right - it's a sort of "zip" algorithm for a prompt-based model's inputs and outputs. Thus, it allows users to compress their request down to the minimal token size which retains the same semantics. This allows a user to encode a more dense set of tokens into the original request.
LLMLingua uses a well-trained small language model after alignment, such as LLaMA-7B, to detect the unimportant tokens in the prompt and enable inference with the compressed prompt in black-box LLMs, achieving up to 20x compression with minimal performance loss.

✨ Abstract
Large language models (LLMs) have demonstrated remarkable capabilities and have been applied across various fields. Advancements in technologies such as Chain-of-Thought (CoT), In-Context Learning (ICL), and Retrieval-Augmented Generation (RAG) have led to increasingly lengthy prompts for LLMs, sometimes exceeding tens of thousands of tokens. Longer prompts, however, can result in 1) increased API response latency, 2) exceeded context window limits, 3) loss of contextual information, 4) expensive API bills, and 5) performance issues such as “lost in the middle.”
Inspired by the concept of "LLMs is Compressors" we designed a series of works that try to build a language for LLMs via prompt compression. This approach accelerates model inference, reduces costs, and improves downstream performance while revealing LLM context utilization and intelligence patterns. Our work achieved a 20x compression ratio with minimal performance loss (LLMLingua), and a 17.1% performance improvement with 4x compression (LongLLMLingua).

Curieo.org is building a revolutionary product on healthcare search, They have obtained the seed funding and they are looking for great MLE and SWE like you.
Check it out:
✨ Details
✨ Let's go deeper 🤪🌀✨
⚡️ Challenges
There are three main challenges when LLMs are used in long context scenarios:
The higher computational and financial costs required to run these models or to call APIs from companies providing LLM services. This can be a significant barrier for individuals or smaller organizations with limited
resources.
The longer latency associated with LLMs can cause delays in generating
responses or predictions and is particularly problematic in real-time scenarios where users expect quick and accurate responses.
The inferior performance is caused by the extended window size of LLMs and the low density as well as the less sensitive position of the question-relevant key information in the prompt.

⚡️ Prologue
There are a couple of good works in that field before the llmlingua that are worth mentioning here.
Token pruning and token merging , which need model fine-tuning or intermediate results during inference have been used with BERT-scale models.
Soft prompt tuning methods like GIST, AutoCompressor, and ICAE (Ge et al., 2023), require LLMs’ parameter fine-tuning, making them suitable for specific domains but not directly applicable to black-box LLMs.
Information-entropy-based approaches such as Selective Context and LLMLingua use a small language model to calculate the self-information or perplexity of each token in the original prompt and then remove tokens with lower perplexities.
🌻 Edition 25: Can we use LLM to improve the AppSec? 🔒🎄

Over the last 12 months, most teams have asked themselves “How can we leverage Gen AI to improve what we are doing”? For AppSec leaders though, the immediate problem statement was about the secure usage of Gen AI. As the dust settles on that (we at least
⚡️ How it Works(From the research paper)
Our main contributions are five-fold:
We propose a question-aware coarse-to-fine compression method to improve the key information density in the prompt.
We introduce a document reordering mechanism to reduce information loss in the middle.
We present dynamic compression ratios to bridge the coarse-grained compression and fine-grained compression for adaptive granular control.
We propose a post-compression subsequence recovery strategy to improve the integrity of the key information.
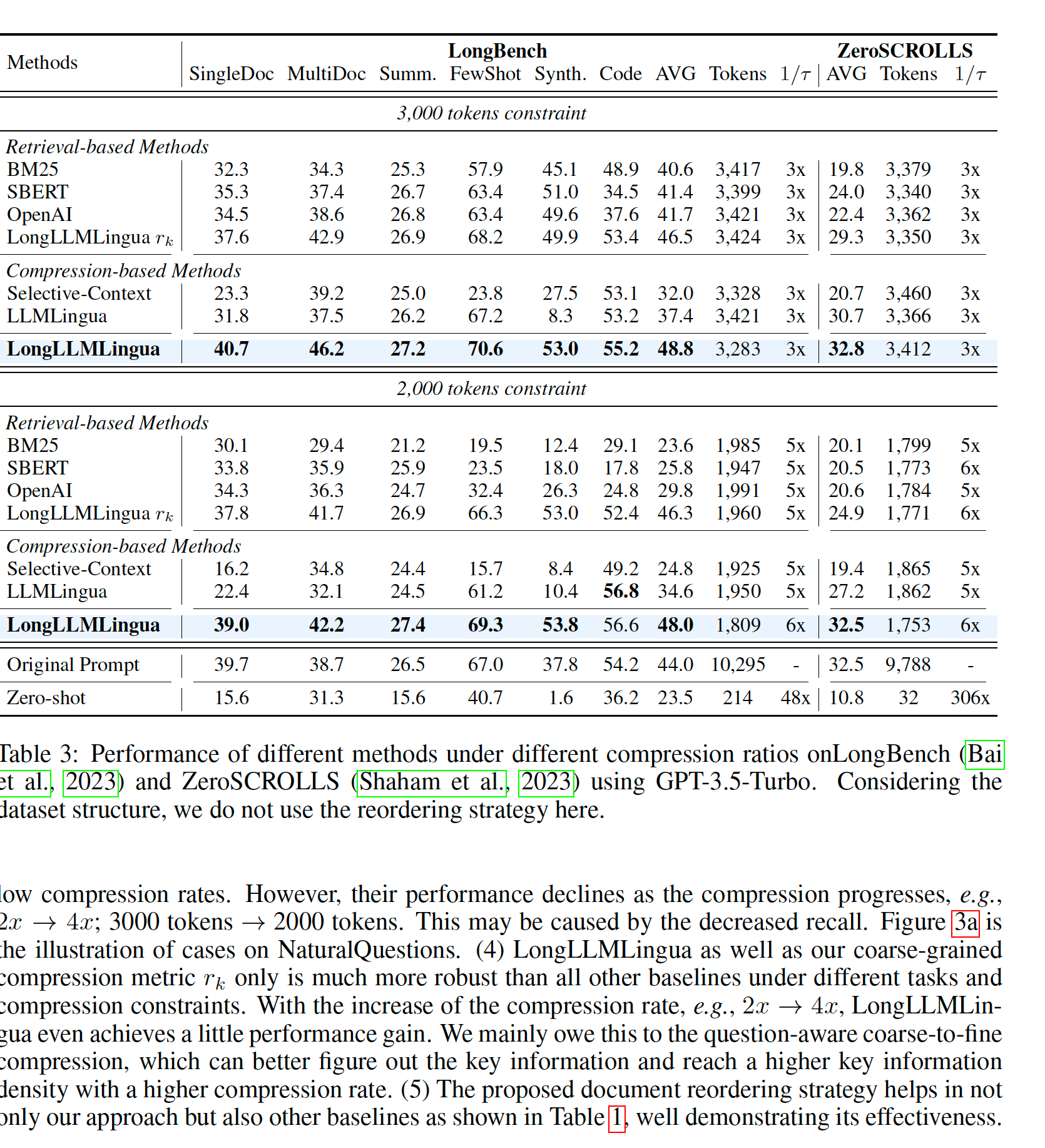
We evaluate LongLLMLingua on three benchmarks, i.e., NaturalQuestions, LongBench, and ZeroSCROLLS.
Experimental results demonstrate that compared with original prompts, LongLLMLingua compressed prompts can achieve higher performance with much lower costs. The latency of the end-to-end system is also reduced.
⚡️ Result
**
I will publish the next Edition on Sunday.
This is the 26th Edition, If you have any feedback please don’t hesitate to share it with me, And if you love my work, do share it with your colleagues.
It takes time to research and document it - Please be a paid subscriber and support my work.
Cheers!!
Raahul
**